
光通信产业链与大横评
MRVL, COHR, CIEN, LITE, FN, CRDO, AAOI, AXTI, ALMU

在人工智能发展史上,大规模语言模型(LLM)的参数量突破万亿级别标志着一个根本性的转折点:数据中心的性能瓶颈已从传统的计算处理极限(Compute-bound)彻底转移至数据传输延迟与带宽限制(Communication-bound)。
光模块已经从传统数据中心架构中的“辅助网络配件”转变为决定 AI 算力集群规模上限的“刚性战略基础设施”。
根据市场预测,全球 800G 及以上速率(含 1.6T)的光模块出货量将从 2025 年的约 2400 万只,激增至 2026 年的近 6300 万只,实现高达 2.6 倍的惊人同比增长 。

1. 光通信产业链
第一环:核心原材料与基底(Substrates)
光通信产业链的最底层是由高度专业化的半导体原材料和晶圆衬底构成的。
这些材料是所有光电转换和信号调制的物理载体。
在 1.6T 时代,传统的硅材料由于其间接带隙的物理特性,无法实现高效的光发射 ,这迫使整个行业极度依赖以磷化铟(InP)和砷化镓(GaAs)为代表的化合物半导体,同时加速引入绝缘体上硅(SOI)和薄膜铌酸锂(TFLN)等新兴平台。
磷化铟(InP)与砷化镓(GaAs)的产能竞逐与技术壁垒
磷化铟(InP)是支撑 1.6T 光模块核心发光组件的绝对战略要地。
InP 具有直接带隙,其发光波长完美契合光纤通信损耗最低的 1310nm 和 1550nm 窗口,且其电子迁移率大约是 GaAs 的两倍,这使其成为制造超高速电吸收调制激光器(EML)的唯一可行基底材料 。
AXT是全球少数几家能提供高纯度磷化铟(InP)和砷化镓(GaAs)半导体衬底晶圆的企业之一,控制着全球约40%的InP市场份额。
硅光子学(SiPh)与薄膜铌酸锂(TFLN)的底层突破
为了打破对纯 InP 衬底的绝对依赖并降低成本,行业正在向硅光子技术(Silicon Photonics)转型。
硅光技术利用绝缘体上硅(SOI)衬底,将微型光学波导、调制器和光电探测器集成在与 CMOS 工艺完全兼容的晶圆上 。
虽然硅本身无法发光,需要外部键合 InP 激光器(如 CW 激光器)作为光源,但硅光技术能够利用极其成熟的大尺寸硅晶圆代工体系,实现无源对准和极高的单片集成度,从而在超大规模量产中展现出压倒性的成本优势 。
在调制器材料的演进中,薄膜铌酸锂(TFLN)成为了 1.6T 时代的“黑马”。
溫度穩定性:TFLN這種材料會根據電壓成正比的改變折射率,因此TFLN可透過電壓來決定訊號的0跟1,且TFLN折射率的溫度係數低,因此熱能對TFLN調變器的影響就不大。
損耗低:TFLN相較於矽,矽對於可見光是不透明的,而TFLN在可見光波端甚至完全透明,使其成為天生具備低衰減特性的優良光學介質。
體積:矽光MZM調變器之所以大,是因為矽在調變速率上比較慢,需要更長的空間給他調變,但TFLN製作的MZM調變器調變速度快於矽光MZM調變器,所以TFLN製作成的MZM會小很多,可能還是比矽光MRM大,但論CP值來說也足夠屌打了。
第二环:核心电芯片(DSP / PAM4 IC)
如果说晶圆基底是地基,那么以数字信号处理器(DSP)和 PAM4 驱动芯片为主的核心电芯片则是 1.6T 光模块的“大脑”。
DSP 的核心任务是在数字域与模拟域之间进行高速转换,执行复杂的脉冲幅度调制(PAM4 或更高阶的 PAM6)编码,并通过复杂的自适应均衡算法和前向纠错(FEC)技术,从严重劣化的眼图中恢复出准确的比特流 。
高不可攀的技术壁垒
设计支持 1.6T 吞吐量的 5nm 甚至 3nm 节点 DSP 芯片,是一项需要耗资数亿美元、耗时数年的工程奇迹。
据预测,全球 PAM4 DSP 市场规模在 2024 年约为 13.5 亿美元,在 AI 浪潮的推动下,到 2033 年将猛增至 64.1 亿美元(CAGR 19.7%)。
架构演进与新兴的铜互联反扑
为了配合下一代单通道 200G 的交换机 ASIC,DSP 厂商已全面转向 8:8 同步架构。
博通的 Sian2 DSP 和 Marvell 的 Nova 2 DSP 均直接瞄准这一下一代架构设计,极大优化了内部信号处理的延迟和功耗 。
在寡头博弈中,Credo 凭借其极具特色的架构开辟了高利润的细分市场。在 VRIO 模型分析中,Credo 的核心竞争力在于其 Bluebird 光学 DSP 能够支持低于 40 纳秒(<40ns)的超低延迟 。
LPO/LRO 架构对 DSP 的生存威胁
虽然 DSP 是不可或缺的纠错大脑,但其惊人的功耗已成为数据中心热管理的噩梦。在一个传统的 400G 或 800G 光模块中,DSP 往往会消耗整个模块近 50% 的电力(如 400G 模块中约占 4W) 。
针对这一痛点,行业发起了“去 DSP 化”的架构革命:线性驱动可插拔光学(LPO)技术。
LPO 方案大胆地从光模块内部彻底移除了 DSP 芯片,完全依赖具有极高线性度的 TIA(跨阻放大器)和 Driver 器件,将模拟信号的均衡和恢复任务强行推回给主机侧的交换机 ASIC 来完成 。
面对 LPO 的颠覆,DSP 巨头们迅速推出折中方案。
那就是线性接收光学(LRO)或称为半重定时模块(Half-retimed modules)。
比如Marvell 推出的 Spica Gen2-T 和 Credo 推出的Dove 850。
第三环:核心光芯片与光学组件(Lasers / Optic Chips)
如果 DSP 是大脑,光芯片(激光器和光电探测器)就是 1.6T 光模块的心脏。
该环节负责将电信号转化为光信号(电光转换,E/O)并发射至光纤网络,以及在接收端完成光电转换(O/E)。
目前,全球光通信供应链最致命的瓶颈正是卡在 1.6T 模块所需的 200G 核心激光器上 。
200G EML 的产能危机与英伟达的战略垄断
EML 将产生连续光波的 DFB 激光器和负责信号编码的电吸收调制器(EAM)单片集成在一块 InP 衬底上。
这种复杂的异质结结构使得其生产门槛极高,全球仅有寥寥数家企业具备量产能力,主要包括 Lumentum、Coherent、三菱(Mitsubishi)、住友(Sumitomo)和博通(Broadcom) 。
CW 激光器与硅光晶圆厂的产能狂奔
被 EML 缺口逼入绝境的云服务商(CSP)和模块厂,正将希望寄托在连续波(CW)激光器与硅光芯片的组合上。
CW 激光器由于无需集成调制器,设计大为简化,制造良率显著高于 EML 。
由 CW 激光器提供纯净光源,配合大产能硅晶圆厂制造的外部硅调制器,成为了规避 InP 产能瓶颈的“泄压阀” 。
第四环:系统集成与高阶相干光(Systems & High-end Modules)
当视角从数据中心内部(Intra-DC)转向数据中心之间(DCI)和跨洋骨干网时,第四环的系统集成和相干传输技术成为了保障海量 AI 数据异地协同的“大动脉”。
1.6T 高阶相干光传输技术
Ciena 推出的 WaveLogic 6 Extreme 堪称嵌入式光引擎的巅峰之作。得益于采用最先进的 3nm 硅工艺打造的相干 DSP 以及超高带宽光电组件,该系统能够在单载波上实现高达 1.6Tb/s 的惊人速率。
与之对标,Infinera(已发布 ICE7 光引擎,支持 1.2T 甚至更高演进)、诺基亚(其 PSE-6s 引擎支持 2.4T 联合传输,宣称能耗降低 60%)以及富士通的 1FINITY 平台,均在这一高端市场中展开激烈的性能角逐 。
架构战争:嵌入式(Embedded)vs 可插拔(Pluggable)
传统嵌入式系统(如 WaveLogic 6)能够提供极限的频谱效率和无与伦比的传输距离,但其设备庞大、封闭且极端昂贵。
相比之下,封装在标准化 QSFP-DD 或 OSFP 外壳中的可插拔相干光模块,能够直接插入通用的以太网路由器和交换机中,彻底消灭了专用的光传输层(IPoDWDM 架构) 。
对于距离小于 120 公里的城域数据中心互联(Metro DCI),谷歌、Meta 等云巨头正压倒性地倒向可插拔架构。
第五环:制造与封装代工(Optical EMS)
第五环是光模块产业链的“兵工厂”。
在这里,前文所述的 InP 激光器、硅光芯片、DSP、透镜和微棱镜等无数微小的光学与电子元件,被以亚微米级的精度集成在一起。
光通信电子制造服务(Optical EMS)已不是传统的流水线组装,而是高度依赖微机电系统(MEMS)对准、激光焊接和金线键合的高精度微纳制造。
封装革命:从 COB 到 3D SiP,以及功耗倒逼的形态变局
随着速率迈向 1.6T,传统的板上芯片(COB)封装,即使用氮化铝(AlN)陶瓷基板平面贴装 EML 和电容,在信号完整性和物理空间密度上已遭遇天花板 。
行业正被强行推向 2.5D 和 3D 的系统级封装(SiP) 。
然而,三维异构集成带来了极其严苛的制造良率挑战。
例如,在使用硅光子芯片作为中介层(Interposer)进行 3D 堆叠时,必须使用高深宽比的博世(Bosch)深反应离子刻蚀技术来制造硅通孔(TSV),同时还要进行极薄的晶圆减薄处理 。
这些极限物理工艺会引入巨大的机械应力和严重的热膨胀失配问题,极易引发微裂纹并导致芯片失效,这也解释了为何掌握高端光电耦合封装技术的代工厂(如台积电、Fabrinet)在当前具有极高的议价能力 。
为了避免数据中心因热量崩溃,三种封装架构展开了博弈:
传统可插拔(TRX): 包含完整 DSP,成熟可靠,具有 FEC 纠错功能,但功耗居高不下(>25W),在 1.6T 时代其热密度已接近风冷物理极限 。
线性驱动可插拔(LPO): 拿掉高功耗的 DSP 芯片,功耗骤降 30%-50%,且降低了延迟。但其致命弱点是信号完整性脆弱,极易受到系统噪声和信号偏斜的影响,且严重依赖主机交换机 ASIC(如博通 Tomahawk 或英伟达特定芯片)的模拟均衡能力,难以形成通用的多供应商互操作生态 。
共封装光学(CPO): 被公认的终极演进形态。CPO 彻底抛弃了可插拔模块的外壳,将光引擎直接与交换机 ASIC 封装在同一块超大基板上 。这种做法将高频电信号的传输距离从十几厘米缩短至几毫米,从物理法则层面消除了信号损耗,实现了最优的能效比和无与伦比的端口密度 。然而,CPO 的集成度过高,一旦个别光通道发生故障,整台造价百万的交换机可能面临无法现场维修的灾难性风险。
第六环:测试与质量保证(Testing & Burn-in)
最后一环是守护数以百万计的 1.6T 模块在极端的电磁、高温和高压环境下不会在数据中心“罢工”的测试与质量保证体系。光通信测试并非简单的抽样质检,而是贯穿芯片设计、信号仿真、协议互通到大规模出厂烤机的系统工程。
测试仪器的度量衡之战与动态链路协商
为了能够捕捉和分析这些“转瞬即逝”的高频信号,头部测试设备提供商如 Keysight、EXFO、Anritsu和 Spirent正在展开激烈的军备竞赛 。
例如,Keysight 推出的 M8050A 能够支持高达 120 GBd 的波特率,并完全兼容 NRZ、PAM4、PAM6 甚至 PAM8 等高阶调制格式,成为 1.6T 路径寻找和预研的利器 。
2. 光通信产业链的厂商 - 大横评
我这里挑选了主要做光通信产业链的厂商, Broadcom、NVidia、Intel、Cisco 也有光通信的业务但不是主营,所以我这里就不提啦。
以下都是我比较感兴趣的标的。
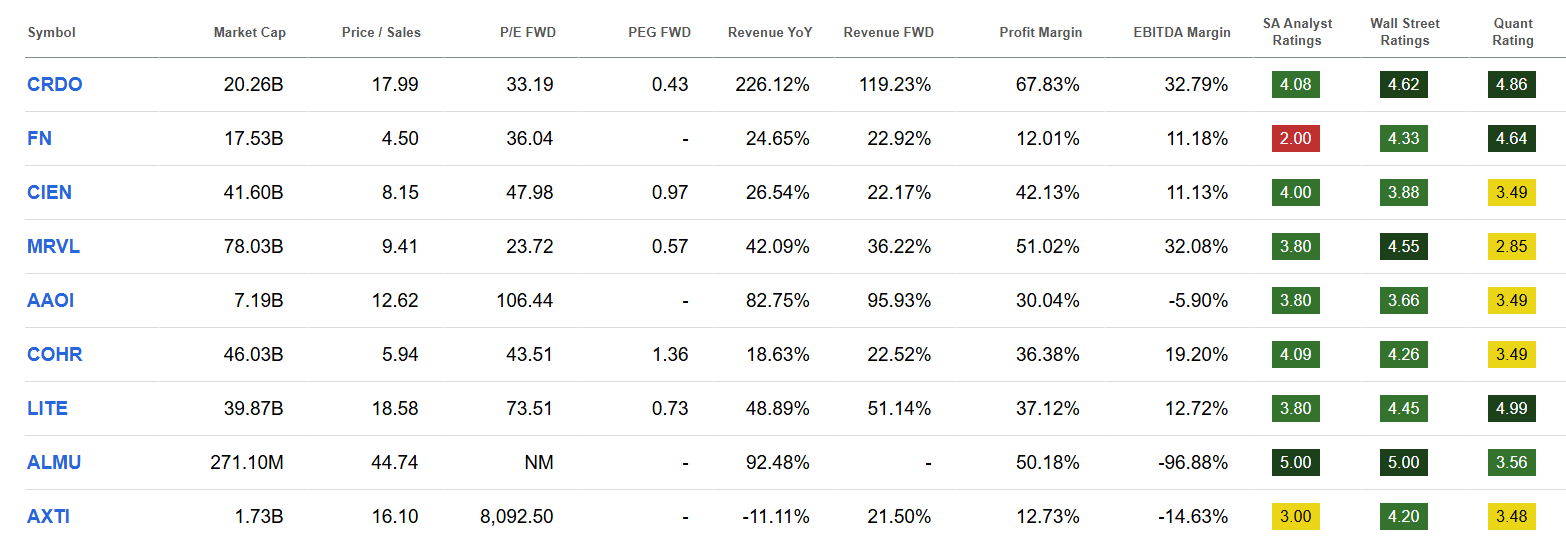
其中:
P/S = P/S (TTM)
Profit margin = Gross profit margin
Quant Rating = Seeking Alpha Quant Rating
SA Analyst Rating = Seeking Alpha Analysts Rating
2.1 Marvell (MRVL):AI互联织物与定制ASIC的绝对霸主
Marvell在2026年已彻底摆脱了“二线”芯片厂的标签,蜕变为与Broadcom分庭抗礼的“AI互联系统架构师”,市值突破780亿美元 。
其核心逻辑在于构建从DSP、交换机到定制计算芯片的“全栈式”网络护城河。
狂飙的财务数据与远期指引: 2026财年第四季度,Marvell总营收达到创纪录的22.19亿美元(同比增长22%),其中数据中心业务营收飙升46%,突破年化60亿美元的大关,占总营收比重高达74% 。管理层给出了震撼华尔街的长期指引:预计FY2027营收接近110亿美元(同比增超30%),而FY2028营收将逼近150亿美元,非GAAP每股收益(EPS)预计突破5美元 。
1.6T DSP的市场垄断: 在PAM4 DSP市场,Marvell凭借其卓越的跨阻放大器(TIA)架构和先发优势,确立了绝对的统治地位。行业分析指出,Marvell在800G DSP中占据了约70%的份额,并在1.6T DSP领域几乎包揽了Google等巨头的全部初期需求 。其首款200G/lane的1.6T Nova 2 DSP已在2026年下半年实现大规模量产交货 。
定制AI芯片 (Custom XPU) 的从0到1: Marvell的定制ASIC业务是其最大的超预期增量。该业务在FY2026实现了15亿美元的营收,并预计在FY2027增长20%以上,至FY2028实现翻倍,达到33亿美元级别 。其深度参与了亚马逊和微软的定制硅片项目,并成功导入了某顶级云厂商下一代旗舰XPU的量产订单 。
前瞻性的CPO战略布局: 通过在2025年以约32.5亿美元收购Celestial AI,Marvell将其独特的“光子织物(Photonic Fabric)”技术纳入麾下 。这一技术致力于解决芯片到芯片、芯片到内存之间的光互联,为未来AI集群实现内存解耦(Memory Disaggregation)和板级光网络奠定了坚实的基础,将成为支撑其FY2028及以后增长的强力引擎 。
2.2 Lumentum (LITE) 与 Coherent (COHR):NVIDIA 40亿美元绑定的光子双雄与产能壁垒
在1.6T光模块的放量周期中,全球产业链遇到了一个坚硬的物理瓶颈:用于制造高速电吸收调制激光器(EML)和连续波(CW)激光器的磷化铟(InP)晶圆产能极度稀缺 。与成熟的硅基晶圆不同,InP外延生长的良率和吞吐量极具挑战。为了确保其“千兆瓦级”AI数据中心的建设不被光器件卡脖子,并出于供应链“近岸化”的安全考量,NVIDIA在2026年3月宣布了一个震撼业界的大动作:分别向Lumentum和Coherent注资20亿美元,并签署了数十亿美元的长期采购协议(LTA) 。这一举动直接将这两家公司升格为AI算力的“战略核心资产”。
Lumentum Holdings (LITE):
业绩爆发与高端定价权: Lumentum成功将业务重心全面转向AI与云数据中心。其Q2 FY2026营收达到创纪录的6.655亿美元(同比增长65.5%),其中通信组件业务大增68.3%。非GAAP营业利润率同比扩大超1700个基点至25.2% 。更关键的是,其100G和200G EML产能已被客户完全“买断”,呈现出极强的卖方定价权。由于200G/lane激光器的平均售价(ASP)远高于100G,产品结构的升级为其带来了巨大的利润弹性 。
系统级跃升:OCS与CPO的爆发: 除了基础激光器芯片,Lumentum的另一大增量来自系统级产品。其光路交换机(Optical Circuit Switch, OCS)积压订单在2026年初已飙升至4亿美元以上,主要面向三家北美超大云厂商,交货集中在2026年下半年 。此外,它还获得了首个价值数亿美元的CPO超大功率外部光源模块(ELS)订单,这标志着其收入模式从单一的“卖芯片”转向了高附加值的“卖子系统”,单项目潜在收入规模可扩大2至2.5倍 。
Coherent Corp (COHR):
1.6T量产与InP晶圆革命: 借助NVIDIA的20亿美元私募注资,Coherent正在其位于美国德克萨斯州Sherman的工厂进行疯狂的产能扩张。其核心战略是利用6英寸InP晶圆技术(相比传统的3英寸晶圆,其单片产出可增加四倍,成本减半)建立断层式的制造成本优势 。公司目标在2026年第四季度前将InP产能翻倍,以承接下半年开始的1.6T收发器“阶梯式”订单暴增 。
前端芯片的深厚积累: Q2 FY2026公司营收达16.9亿美元(同比增长17.5%),数据中心业务暴增33.5%,该领域的订单出货比(Book-to-bill)高达惊人的4.0x 。除了模块的垂直整合制造,Coherent还展露了其在高速模拟芯片领域的实力,推出了CHR1074 224Gbps四通道TIA放大器。该芯片具有50纳秒的极速链路恢复能力,完美契合了AI超算网络对突发模式(Burst-mode)和功耗管理的严苛要求 。
2.3 Ciena (CIEN):相干光霸主与AI大动脉的承建者(WaveLogic 6)
如果说Marvell和Lumentum解决的是数据中心“内部(Intra-DC)”的血管互联,Ciena解决的则是连接这些孤立数据中心、实现分布式AI协同训练的“大动脉(Data Center Interconnect, DCI)”问题。
超预期指引与积压订单: 由于云厂商(Hyperscalers)和新兴算力租赁商(Neoscalers)对“跨数据中心扩展(Scale-Across)”网络带宽的极度饥渴,Ciena迎来了业绩的全面重估。公司将其FY2026目标营收大幅上调至59亿至63亿美元,并手握高达70亿美元的创纪录积压订单 。在Q1 FY2026,其营收达1.43亿美元,同比增长33%,其中云端相关收入已占总营收的一半以上 。
WaveLogic 6 的商业碾压: 2026年是Ciena第六代相干光引擎 WaveLogic 6 (WL6) 全面统治市场的年份。WL6 Extreme (WL6e) 作为行业首款1.6T相干引擎,能够在中长距光纤上实现单波长1.6 Tb/s的超大容量传输,相较上一代将每比特功耗和空间占用降低了50%。它已被用于印度Constl的1450公里骨干网和欧洲euNetworks的商用网络中 。与此同时,WL6 Nano 则以800G相干可插拔模块(Pluggables)的形式,大幅降低了功耗门槛,直接服务于边缘数据中心和城域网 。目前,全球已有超过90家客户承诺部署WL6架构,确立了Ciena在高端相干传输领域领先竞争对手近两年的代际优势 。
2.4 Fabrinet (FN):1.6T高端精密制造的枢纽与地缘产能避风港
在高度复杂且容错率极低的光模块供应链中,Fabrinet扮演着不可或缺的“高级精密代工”角色,尤其是在高精度的光学对准、测试与硅光子封装领域。
AI硬件的制造支柱: 凭借为NVIDIA以及行业龙头的模块厂提供1.6T互联模块的组装服务,Fabrinet深度绑定了AI资本支出的红利。令人瞩目的是,Fabrinet几乎占据了NVIDIA Blackwell平台配套1.6T光模块100%的制造份额 。其财报表现极为强劲,Q3 FY2026营收指引高达11.5亿至12.0亿美元,非GAAP EPS指引达3.45-3.60美元,反映出34%的年度预期增长,完全摆脱了传统电信市场疲软的拖累 。
“厂中厂”模式与产能护城河: 面对汹涌的1.6T订单和日益严峻的地缘政治风险,Fabrinet正在泰国春武里(Chonburi)加速建设占地200万平方英尺的10号工厂(Building 10),预计2026年中期至年底分批投入使用 。该工厂的建成将使其1.6T产能实现翻倍,每年新增高达24亿美元的产值潜力。其独创的“厂中厂(Factory-in-a-Factory)”闭环生态以及在东南亚的深耕,使其在当前中东物流阻断、全球供应链震荡的环境下,展现出了极高的交付韧性和客户黏性 。
2.5 Credo Technology (CRDO):AEC与MicroLED ALC架构的颠覆者
Credo在2026年是互联市场中最具爆发力的“黑马”。其避开了与Marvell在传统DSP领域的正面交锋,专注于低功耗、高可靠性的非标准光电替代方案,走出了一条差异化的高速增长路径。
财务数据的爆炸式增长: Q3 FY2026,Credo交出了一份震撼市场的答卷,单季营收达4.07亿美元,环比增长近52%,同比暴增超过200%。非GAAP毛利率高达68.6% 。这得益于四大北美超大云服务商(每家贡献均超10%总营收)对其 有源电缆 (Active Electrical Cables, AEC) 产品的大规模采购 。AEC内置了SerDes重定时器,以不到光模块一半的功耗提供了近乎铜线的可靠性,目前已成为AI集群机架内(<7米)连接的事实标准。xAI等巨头明确背书其“零软链路抖动(ZeroFlap)”技术,以保障十万卡级RDMA网络训练的绝对稳定性 。
Active LED Cable(ALC)的发布: 深刻认识到铜线在跨机架(Row-scale,超过7米至30米)传输中的物理极限,Credo在2025年底前瞻性地收购了MicroLED光互联初创企业Hyperlume 。在Q2FY26的earnings call,Credo正式向市场推出了ALC类别。该产品将Credo卓越的SerDes架构与MicroLED高密度、低功耗发光阵列完美结合,旨在提供与AEC同等的高可靠性和低功耗,同时实现长达30米的光纤传输距离 。这一颠覆性产品直击传统LPO和DSP光模块在机架间互联中存在的功耗及成本痛点,极大地扩展了Credo的总潜在市场(TAM),成为支撑其FY2027保持50%以上高增长的核心武器 。
2.6 Applied Optoelectronics (AAOI):垂直整合优势与美国本土产能的溢价释放
在高度分工的光模块产业中,Applied Optoelectronics 凭借其独特的“内部激光器晶圆制造 + 自动化收发器组装”的垂直整合模式,在2026年迎来了史诗级的价值重估 。
破除InP瓶颈与巨头大单落地: 随着1.6T时代的到来,无厂(Fabless)模块厂商普遍面临InP激光二极管产能受制于人的生死困境。AAOI凭借自有的激光器晶圆厂,成功规避了这一供应链卡脖子问题。2026年3月,公司确认获得了来自超级计算巨头(普遍推测为微软和亚马逊)的第四批800G大规模订单,彻底解决了此前的固件定制化适配问题,其产品正式进入放量期 。
“美国制造”的安全溢价: 为迎合北美云厂商在当前地缘局势下对“供应链安全(Supply Chain Security)”的极致追求,AAOI投入2.09亿美元在其位于美国德克萨斯州Sugar Land的总部大幅扩建生产线 。尽管美国本土制造的基础成本高出10%-15%,但高度自动化的产线和本土供应链的稳定性完美消化了这部分溢价。公司给出了极其强悍的指引:目标在2026年底前实现每月超过50万只的800G/1.6T模块产能(其中25%来自德州工厂),预计2026年总营收将突破10亿美元,并在2027年中期实现每月近3.78亿美元的收发器收入 。
2.7 AXT Inc (AXTI):InP衬底的底层垄断与出口管制的艰难博弈
作为光通信产业链的“基座”,AXT是全球少数几家能提供高纯度磷化铟(InP)和砷化镓(GaAs)半导体衬底晶圆的企业之一,控制着全球约40%的InP市场份额。InP是制造800G和1.6T不可或缺的EML和CW激光器的核心材料。
海量需求与产能翻倍计划: 乘着AI光互联的东风,AXT的底层材料需求呈现出爆发式增长,订单积压迅速超过6000万美元,并开始获得更多过去难以触及的一线(Tier-1)客户长单。公司自2025年10月起已扩充25%的产能,并设定了在2026年底前将InP总产能翻倍的宏大目标,剑指6英寸晶圆以及未来CPO技术的庞大增量 。
地缘政治的阿喀琉斯之踵: 然而,AXT的致命弱点在于其生产基地主要位于中国北京。自2023年起,中国商务部对关键材料实施的出口管制政策,直接扼住了AXT的营收咽喉。由于许可证审批节奏不可控,公司2025年Q4营收仅为2300万美元,大幅不及市场预期的2700万美元 。进入2026年Q1,虽然公司表示已获得部分出口许可,并给出2600万美元的明确营收指引(若获更多许可则有上行空间),但这种高度不可预测的非商业性壁垒,导致其股价表现出极其剧烈的波动(Beta值高达1.96) 。此外,子公司北京同美(Tongmei)在科创板(STAR Market)的IPO虽已获上交所批准,但仍受制于中国证监会(CSRC)的最终审核,这笔潜在的巨额募资对AXT后续应对全球产能重构至关重要 。
2.8 Aeluma (ALMU):异质集成与量子点技术的未来赌注
区别于上述已在财务报表上兑现AI红利的成熟企业,Aeluma代表了光通信在下一代材料学和基础物理层面的战略押注。
技术范式跃迁: 传统的高性能激光器(InP/GaAs)虽然性能卓越,但受限于晶圆尺寸小(通常为3至6英寸)且成本高昂;而传统的硅光子技术虽然能利用大尺寸硅晶圆(8至12英寸)低成本制造光波导和调制器,但硅本身是极差的发光材料。Aeluma的核心护城河在于其专有的“异质集成平台”——能够将高性能的III-V族化合物半导体(如用于激光器的量子点增益介质、用于高速光电探测器的InGaAs)直接外延生长在大尺寸、与CMOS工艺兼容的硅基板上 。这一突破不仅有望将光电器件的制造成本降低数个数量级,更为未来的极高密度CPO光电融合扫清了障碍。
2026年:商业化验证的关键窗口: 2026年是Aeluma从由政府合同资助的纯R&D机构向商业化批量交付过渡的关键年份。公司已获得来自DARPA(1170万美元)、NASA(量子领域)、美国海军等多项具有极高技术验证价值的军工与航天合同 。其针对AI基础设施数据中心互联(1.6T及以上速率)研发的高速光电探测器已取得实质性进展。在2026年3月的OFC大会和ROTH年度会议上,Aeluma密集展示了其量子点激光器与硅光子集成技术,管理层亦确认已开始收到商业客户的询价与初始小额订单。虽然当前营收体量(TTM约500万美元)仍处于初创期,但资本市场已开始提前定价其技术颠覆带来的长期期权价值 。
总结
2026年是全球光通信网络被AI算力“强制升维”的分水岭。
综合上述分析,得出以下三个维度的核心论断与投资指引:
第一,“互联即计算(The Network Is the Compute Fabric)”从概念落地为财报数据,核心利润持续向上游高壁垒环节转移。
1.6T时代的到来不是简单的速率翻倍,而是伴随着深刻的底层硬件重构。
从Marvell交出的15亿美元定制ASIC营收与1.6T DSP的统治级表现,到Lumentum/Coherent手握的40亿美元NVIDIA“投名状”与脱销的200G EML产能,清晰地揭示了一个规律:在这个超级周期中,最丰厚的利润不再属于那些仅仅进行PCB组装的传统模块厂,而是被掌握核心底层芯片(如DSP、TIA、SerDes)设计能力,以及拥有高端基础光电器件(如InP外延晶圆、硅光引擎)制造霸权的源头企业所攫取。
因此,具有深厚底层IP积累与垂直制造能力的Marvell、Lumentum和Coherent,应享有系统级的估值溢价。
第二,网络拓扑的异构化带来“多技术路线共荣”,应精准押注各自领域的细分王者。
市场此前对“CPO是否会迅速消灭可插拔模块”或“LPO是否会取代DSP”的非黑即白式担忧已被证伪。2026年的真实场景是按距离和功耗严格分层的异构网络:
WAN与跨数据中心(Scale-Across): 在这个对长距传输和多协议互操作性要求极高的领域,基于先进DSP的相干光架构依然是霸主,Ciena 凭借WaveLogic 6建立的两年技术代差,将独享这一块高达百亿美元的DCI市场红利。
叶脊网络与Scale-Out(5m-50m): 面对能耗墙,LPO/LRO 以及结合了硅光子的方案将迎来爆发式增长,占据这一层级的主要份额。
机架内与超密集群(<30m): 在解决RDMA网络“软链路抖动”的刚需下,Credo 开创的AEC以及极具前瞻性的 MicroLED ALC 技术,以极低的功耗和无与伦比的可靠性,形成了对传统VCSEL光模块的“降维打击”。对于风险偏好较高的资本,Credo的持续高成长性及其在非标准连接领域的颠覆能力具有极高的配置价值。
CPO(光电共封装): 作为终极解,CPO正由NVIDIA和Broadcom强力推进,而Marvell通过收购Celestial AI掌握了光子织物底座,Aeluma则通过异质集成致力于打破成本边界,这两者是布局长期CPO红利的绝佳抓手。
第三,供应链的政治与地理属性已成为企业核心竞争力的关键一环。
在2026年,地缘博弈的阴影无处不在。AXTI 所陷入的中国出口管制泥沼深刻警示了“单点地缘依赖”的巨大风险,无论其底层技术和需求多么强劲,不可预测的行政指令都能瞬间摧毁其营收的连贯性,该标的应被视为高风险的事件驱动型期权。
反之,能够通过“本土化扩产(如AAOI 的德州工厂)”或建立“高韧性闭环代工体系(如 Fabrinet 的泰国矩阵)”来抵御全球物流中断(如霍尔木兹海峡危机)的企业,将斩获那些将“供应链安全”视作第一要务的云巨头长单,从而获得估值重塑的机会。